
深度学习结合SLAM 研究现状总结
1. 用深度学习方法替换传统slam中的一个/几个模块:
特征提取,特征匹配,提高特征点稳定性,提取点线面等不同层级的特征点。
深度估计
位姿估计
重定位
其他
目前还不能达到超越传统方法的效果,
相较传统SLAM并没有很明显的优势(标注的数据集少且不全,使用视频做训练数据的非常少。
SLAM中很多问题都是数学问题,深度学习并不擅长等等原因)。
2. 在传统SLAM之上加入语义信息
图像语义分割
语义地图构建
语义SLAM算是在扩展了传统SLAM问题的研究内容,现在出现了一些将语义信息集成到SLAM的研究,
比如说用SLAM系统中得到的图像之间的几何一致性促进图像语义分割,
也可以用语义分割/建图的结果促进SLAM的定位/闭环等,前者已经有了一些研究,
不过还是集中于室内场景,后者貌似还没有什么相关研究。
如果SLAM和语义分割能够相互促进相辅相成,应该能达到好的效果。
另:使用SLAM帮助构建大规模的图像之间有对应关系的数据集,
可以降低深度学习数据集的标注难度吧,应该也是一个SLAM助力深度学习的思路。
3. 端到端SLAM
其实端到端就不能算是SLAM问题了吧,SLAM是同步定位与地图构建,端到端是输入image输出action,没有定位和建图。
- 机器人自主导航(深度强化学习)等
1. 用深度学习方法替换传统slam中的一个/几个模块:
A. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
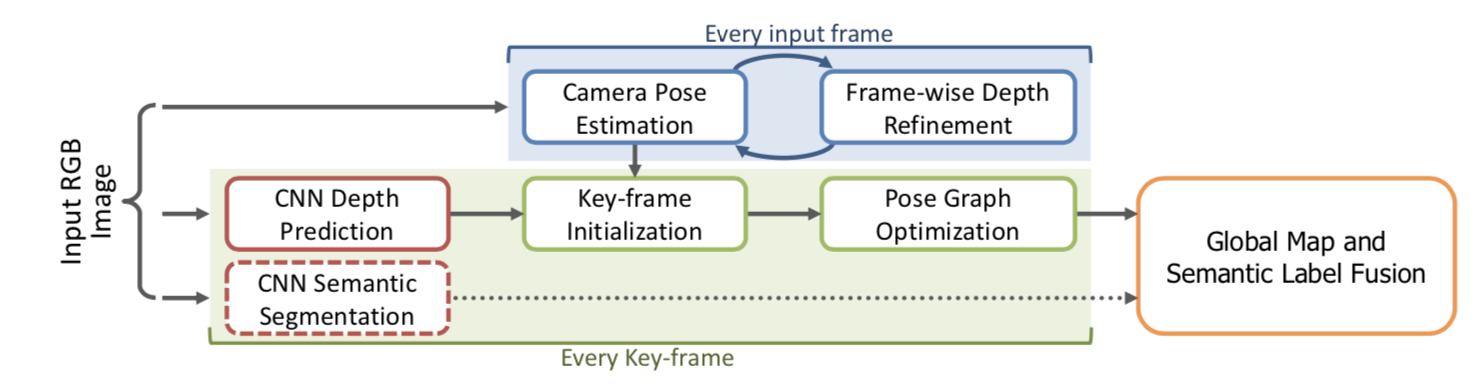
基于CNN的单张图深度估计,语义SLAM,半稠密的直接法SLAM.
将LSD-SLAM里的深度估计和图像匹配都替换成基于CNN的方法,取得了更为robust的结果,并可以融合语义信息.
鉴于卷积神经网络(CNN)深度预测的最新进展,
本文研究了深度神经网络的预测深度图,可以部署用于精确和密集的单目重建。
我们提出了一种方法,其中CNN预测的稠密深度图与通过直接单目SLAM获得的深度测量自然地融合在一起。
我们的融合方案在图像定位中优于单目SLAM方法,例如沿低纹理区域,反之亦然。
我们展示了使用深度预测来估计重建的绝对尺度,从而克服了单眼SLAM的主要局限性之一。
最后,我们提出一个框架,从单个帧获得的语义标签有效地融合了密集的SLAM,从单个视图产生语义相干的场景重构。
两个基准数据集的评估结果显示了我们的方法的鲁棒性和准确性。 ## B. DenseSLAM 使用CNN+DeCNN+RNN 
它接受当前RGB图像 It,以及来自迁移级的隐藏状态 h(t-1),通过LSTM单元进行内部转移。
网络的输出是稠密地图 Zt, 以及相机的姿态 Rt, Tt.
网络结构:

网络结构的另一个参数是时间窗口的大小N=10.
2. Vision Semantic SLAM 视觉分割SLAM 语义SLAM
SLAM的另一个大方向就是和深度学习技术结合。
到目前为止,SLAM的方案都处于特征点或者像素的层级。
关于这些特征点或像素到底来自于什么东西,我们一无所知。
这使得计算机视觉中的SLAM与我们人类的做法不怎么相似,
至少我们自己从来看不到特征点,也不会去根据特征点判断自身的运动方向。
我们看到的是一个个物体,通过左右眼判断它们的远近,
然后基于它们在图像当中的运动推测相机的移动。
很久之前,研究者就试图将物体信息结合到SLAM中。
例如文献[135-138]中就曾把物体识别与视觉SLAM结合起来,构建带物体标签的地图。
另一方面,把标签信息引入到BA或优化端的目标函数和约束中,
我们可以结合特征点的位置与标签信息进行优化。
这些工作都可以称为语义SLAM。
语义和SLAM看似是两个独立的模块,实则不然。
在很多应用中,二者相辅相成。
一方面,语义信息可以帮助SLAM提高建图和定位的精度,特别是对于复杂的动态场景。
传统SLAM的建图和定位多是基于像素级别的几何匹配。
借助语义信息,我们可以将数据关联从传统的像素级别升级到物体级别,提升复杂场景下的精度。
另一方面,借助SLAM技术计算出物体之间的位置约束,
可以对同一物体在不同角度,
不同时刻的识别结果进行一致性约束,从而提高语义理解的精度。
综合来说,SLAM和语义的结合点主要有两个方面:
1、 语义帮助SLAM。
传统的物体识别、分割算法往往只考虑一幅图,
而在SLAM中我们拥有一台移动的相机。
如果我们把运动过程中的图片都带上物体标签,就能得到一个带有标签的地图。
另外,物体信息亦可为回环检测、BA优化带来更多的条件。
2、 SLAM帮助语义。
物体识别和分割都需要大量的训练数据。
要让分类器识别各个角度的物体,需要从不同视角采集该物体的数据,然后进行人工标定,非常辛苦。
而SLAM中,由于我们可以估计相机的运动,可以自动地计算物体在图像中的位置,节省人工标定的成本。
如果有自动生成的带高质量标注的样本数据,能够很大程度上加速分类器的训练过程。
在深度学习广泛应用之前,我们只能利用支持向量机、条件随机场等传统工具对物体或场景进行分割和识别
或者直接将观测数据与数据库中的样本进行比较[108,140],尝试构建语义地图[138,141-143]。
由于这些工具本身在分类正确率上存在限制,所以效果也往往不尽如人意。
随着深度学习的发展,我们开始使用网络,越来越准确地对图像进行识别、检测和分割[144-149]。
这为构建准确的语义地图打下了更好的基础[150]。我们正看到,逐渐开始有学者将神经网络方法引入到SLAM中的物体识别和分割,
甚至SLAM本身的位姿估计与回环检测中[151-153]。
虽然这些方法目前还没有成为主流,但将SLAM与深度学习结合来处理图像,亦是一个很有前景的研究方向。
语义slam应用: 
首先,目前理解的语义的定义的先明确下:
1)图像的标注,即特定目标的识别定位与三维重建,
并将定位信息与识别标签与SLAM的位置信息结合,
实现基于SLAM的三维空间的场景物体打标与模型构建,即图像的内容结构化;
2)标注图像与场景其他物体之间的关系,即所说的场景理解,
将整个场景的图像内容以故事描述的方式串联起来,
构成完成的图像场景信息,及图像内容的语义化。
第二部分基本属于纯粹的语法语义理解的范畴,脱离图像信息的研究内容,目前工作涉及不多,
暂就第一部分及受邀内容涉及的结合点简单讲述下:
1)SLAM对应的是3维点云信息;
2)图像语义信息的低层级信息,即为特定对象的目标识别定位;
3)特定对象的分割、识别定位信息与3DSLAM点云信息的结合,实现3D模型跟踪与重建;
4)将3D目标对象插入到SLAM得到的空间位置序列中。
A. orbslam2 + ssd物体检测实现3d物体分割

场景映射 semantic Mapping : SLAM定位和建图
目标检测和场景分割 bject Detection and Semantic Segmentation : RCNN\YOLO\SSD
基本框架图如下:
输入RGB-D图像 -> ORB-SLAM2应用于每一帧->
SSD(Single Shot MultiBox Detector)用于每一个关键帧进行目标检测,3D无监督分割方法对于每一个检测结果生成一个3D点云分割 ->
使用类似ICP的匹配值方法进行数据关联,以决定是否在地图中创建新的对象或者跟已有对象建立检测上的关联 ->
地图对象的3D模型(3D点云分割,指向ORB-SLAM2中位姿图的指针,对每个类别的累计置信度)
利用现在检测速度很快的SSD,以及基本上可以达到实时定位的ORB-SLAM2相互促进。
然后通过把深度图进行划分,物体检测,最终输出带有语义信息的语义地图。
个人觉得,本文的难点在数据的融合,也就是流程图的第三部分,两者之间怎么去相互配合。
其次本文作者比较谦虚的承认:
为什么没有取名为语义SLAM,是因为该工作只是用SLAM促进分割,并没有用语义分割去促进定位。
实际上两者应该是相辅相成的,只不过貌似后者还没有人做罢了。
本文在实时性和计算量应该算是比较合理的,一般GPU应该能跑起来;缺点是地图可读性比较差。
由于需要非常精确的图像分割,所以本文利用Depth图来帮助分割。
所以需要对Depth进行分割的算法,本文采用了文章@Felzenszwalb2004@Pham2016Geometrically等人的算法。
也是涉及到基于图的分割的过程。
数据关联 Data Association
当完成了把3D Point投影到识别的物体后,数据关联要做的事:
判断检测到的物体是否已经在已经构建的地图中存在了呢,
如果不存在的话,就需要新增这个物体。
通过一个二阶的流程来实现:
对于每一个检测到的Object,根据点云的欧式距离,来选择一系列的Landmarks(已经检测到并在地图里面已经有的Object)
对Object和Point Cloud of landmark进行最近邻搜索,使用了k-d tree来提高效率,
其实这一步也就是判断当前图像检测到的Object与已有的地图中的Landmark(Object)是否相匹配。
在第二步中,如果多余50 % 的Points的都距离小于2cm的话,就说明这个检测到的Object已经存在了。
这个也就是把CNN的分割结果与地图中的Object进行关联起来,并用颜色表示Map中Object的类别。
在上一篇SematicFusion中,采用的Recursive Bayesian 的更新规则来完成地图更新的!
看来,这个是CNN与传统的SLAM框架结合的时候的一个需要解决的问题,
那就是如何把新来的物体与已有的地图中的物体相互关联起来,并更新!
Meaningful Maps With Object-Oriented Semantic Mapping
B. 单目 LSD-SLAM + CNN卷积网络物体分割
基本框架图如下:
输入RGB图像->选择关键帧并refine->2D语义分割->3D重建,语义优化
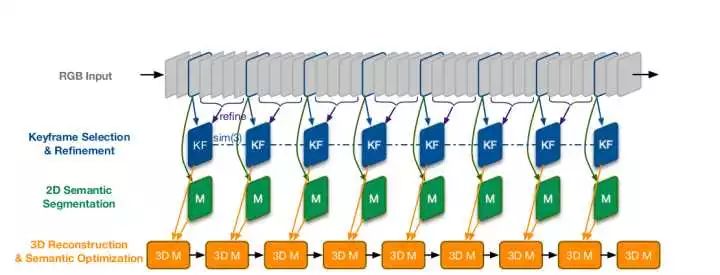
东南大学的一个同学做的,算是参考文献就6页的神文,CVPR2016最佳论文之一。 [论文](https://arxiv.org/pdf/1611.04144v1.pdf)
大致思路:
利用LSD-SLAM作为框架,结合CNN进行有机融合,
选择关键帧进行做深度学习实现语义分割,之后选择相邻的几帧做增强。
C. 数据联合RNN语义分割+ KinectFusion跟踪(rgbdslam) =3d Semantic Scene
看得出来,RNN在帮助建立相邻帧之间的一致性方面具有很大的优势。
本文利用可以实现Data Associate的RNN产生Semantic Label。然后作用于KinectFusion,来插入语义信息。
所以本文利用了RNN与KinectFusion来实现语义地图的构建! [DA-RNN 代码](https://github.com/Ewenwan/DA-RNN)
高层特征具备更好的区分性 , 同时帮助机器人更好完成数据关联 . DARNN [66] 引入数据联合
(Data association, DA) 下的 RNN (Recurrent neural network),
同时对 RGBD 图像进行语义标注和场景重建 .
将 RGB 图像 和 深度图像 分别输入全卷积网络 , 在反卷积层加入 数据联合 RNN 层 ,
将不同帧图像的特征进行融合 , 同时能够融合 RGBD 图像和深度图像 .
该文章使用 KinectFusion [67] 完成相机的跟踪 , 估计当前相机的 6DOF 位姿 ,
将 3D 场景表示为 3D 体素 , 保存于 TSDF (Truncated signed distance function).
本文利用可以实现Data Associate的RNN产生Semantic Label。然后作用于KinectFusion,来插入语义信息。
所以本文利用了RNN与KinectFusion来实现语义地图的构建!
本文采用了DA-RNN与KinectFusion合作的方式来产生最终的Semantic Mapping,
而文章采用的则是ORB-SLAM与CNN结合,他们有一些共同的结构,如Data Associate,虽然我现在还不明白这个DA具体得怎么实现!?
D. SLAM++
语义地图表示为一个图网络 , 其中节点有两种 :
1) 相机在世界坐标系的位姿 ;
2) 物体在世界坐标系的位姿 .
物体在相机坐标系的位姿作为网络中的一个约束 , 连接相机节点和物体节点 .
另外网络中还加入了平面结构等约束提高定位的精度 . ## E. MO-SLAM (Multi object SLAM)
对于场景中重复出现的物体进行检测 , 该方法不需要离线训练以及预制物体数据库 .
系统将重建的路标点分类 , 标记该点所属的物体类别 .
一个物体表示为一个路标点集合 , 相同的物体的不同实例的路标点之间存在如下关系:
P2 = E * P1
系统对于生成的关键帧建立 ORB 描述子的单词树 , 在新的关键帧和候选关键帧之间进行汉明距离匹配 .
如果匹配点的数量不够 , 那么识别线程停止处理当前帧 , 等待下一个关键帧 .
使用 RANSAC (Random sample consensus, 随机采样序列一致性) 框架初始化一个位姿变换 ,
F. SemanticFusion: 卷积-反卷积语义分割cnn(基于caffe) + ElasticFusion(稠密SLAM) + CRF融合

Dense 3D Semantic Mapping with Convolutional Neural Networks 论文
ElasticFusion: Real-Time Dense SLAM and Light Source Estimation 论文
主要框架,用到了ElasticFusion和CNN来产生稠密的Semantic Mapping.
偏重怎样结合CNN搭建一套稠密语义SLAM的系统。SemanticFusion架构上主要分为三部分:
1) 前面提到过的ElasticFusion这种稠密SLAM来计算位姿并建出稠密地图;
稠密SLAM重建目前也相对比较成熟,
从最开始的KinectFusion(TSDF数据结构 + ICP),
到后来的InfiniTAM(用哈希表来索引很稀疏的voxel),
ElasticFusion(用surfel点表示模型并用非刚性的图结构),
DynamicFusion(引入了体翘曲场这样深度数据通过体翘曲场的变换后,
才能融入到TSDF数据结构中,完成有非刚性物体的动态场景重建)都做的比较成熟。
工业界实现非常好的是微软的HoloLens,在台积电的24核DSP上把mesh simplification这些操作都搞了上去。
2) CNN用RGB或RGBD图来生成一个概率图,每个像素都对应着识别出来的物体类别;
3)通过贝叶斯更新(CRF,条件随机场)来把识别的结果和SLAM生成的关联信息整合进统一的稠密语义地图中。
本文的算法,利用SLAM来实现2D Frame与3D Map之间的匹配(Corresponding)。
通过这种方式,可以实现把CNN的语义预测以概率的方式融合到Dense semantically annotated map.
为什么选择ElasticFusion呢,是因为这种算法是surfel-based surface representation,可以支持每一帧的语义融合。
比较重要的一点是,通过实验说明,引入SLAM甚至可以提高单帧图像的语义分割效果。
尤其在存在wide viewpoint variation,可以帮助解决单目2D Semantic中的一些Ambiguations.
之前存在方法使用Dense CRF来获得语义地图。
本文的主要不同是:利用CNN来产生语义分割,然后是在线以 Incremental 的方式生成Semantic Map。即新来一帧就生成一帧的语义地图。
G. Pop-up SLAM: Semantic Monocular Plane SLAM for Low-texture Environments
概述
好像用LSD SLAM的双目图像 得到深度信息 然后直接构建三维环境(反正是低纹理地区 很好建)
在低纹理条件下(这里可能已经是3D图了?)提取边界线,然后选择地线(这个例子里面分割出地面和门 ) ,
然后构建三维建模 感觉只适用于室内的没什么杂物的环境内,规格化场景可以使用。
H. ros_object_analytics 单帧点云(pcl模型平面分割+欧氏距离聚类物体分割) + Yolo_v2(GPU) / MobileNet_SSD(VPU NCS加速棒) 物体检测
使用pcl算法提供的点云 多平面模型分割 和 多目标欧氏距离聚类分割算法 对单帧 RGBD相机捕获的点云 进行分割, 得到3d分割
使用 Yolo_v2(GPU) / MobileNet_SSD(VPU NCS加速棒) 物体检测算法对 RGB图像进行物体检测, 得到2d检测框
两者根据位置信息进行融合,得到物体的 3d标注框
I. Co-Fusion CRF图像分割 + ElasticFusion(RGBD-SLAM)
论文 Co-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects
J. MaskFusion ElasticFusion(RGBD-SLAM) + 语义分割mask-rcnn
论文 MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
本文提出的MaskFusion算法可以解决这两个问题,首先,可以从Object-level理解环境,
在准确分割运动目标的同时,可以识别、检测、跟踪以及重建目标。
分割算法由两部分组成:
1. 2d语义分割: Mask RCNN:提供多达80类的目标识别等
2. 利用Depth以及Surface Normal等信息向Mask RCNN提供更精确的目标边缘分割。
上述算法的结果输入到本文的Dynamic SLAM框架中。
使用Instance-aware semantic segmentation比使用pixel-level semantic segmentation更好。
目标Mask更精确,并且可以把不同的object instance分配到同一object category。
本文的作者又提到了现在SLAM所面临的另一个大问题:Dynamic的问题。
作者提到,本文提出的算法在两个方面具有优势:
相比于这些算法,本文的算法可以解决Dynamic Scene的问题。
本文提出的算法具有Object-level Semantic的能力。
所以总的来说,作者就是与那些Semantic Mapping的方法比Dynamic Scene的处理能力,
与那些Dynamic Scene SLAM的方法比Semantic能力,在或者就是比速度。
确实,前面的作者都只关注Static Scene, 现在看来,
实际的SLAM中还需要解决Dynamic Scene(Moving Objects存在)的问题。}

每新来一帧数据,整个算法包括以下几个流程:
1. 跟踪 Tracking
每一个Object的6 DoF通过最小化一个能量函数来确定,这个能量函数由两部分组成:
a. 几何的ICP Error;
b. Photometric cost。
此外,作者仅对那些Non-static Model进行Track。
最后,作者比较了两种确定Object是否运动的方法:
a. Based on Motioin Incosistency
b. Treating objects which are being touched by a person as dynamic
2. 分割 Segmentation
使用了Mask RCNN和一个基于Depth Discontinuities and surface normals 的分割算法。
前者有两个缺点:物体边界不精确、运行不实时。
后者可以弥补这两个缺点, 但可能会Oversegment objects。
3. 融合 Fusion
就是把Object的几何结构与labels结合起来。
K. DeLS-3D 全深度卷积 语言SLAM CNN+RNN 预测相机位姿态 + CNN+DECNN(卷积+反卷积)2d语义分割
DeLS-3D: Deep Localization and Segmentation with a 2D Semantic
在Localization中,传统的做法是基于特征匹配来做,但这样的坏处是,如果纹理信息较少,那么系统就不稳定,会出错。
一种改进办法是利用深度神经网络提取特征。实际道路中包含大量的相似场景以及重复结构,所以前者实用性较差。
相机的姿态信息可以帮助3D语义地图与2D标签地图之间的像素对应。反过来,场景语义又会帮助姿态估计。
总的工作流程:

从图中可以看出,RGB Images 以及 根据GPS/IMU获得的semantic label map被输入到Pose CNN,
然后输出的Pose信息输入到 Pose RNN来对Pose进一步提高,这里用RNN来获得前后帧的一致性!
然后在利用新得到的Pose来获取更精确的Semantic Label Map,
最后,这个label Map以及RGB图像输入到Segment CNN来进一步提高语义地图的精度。
这里标签地图被用于提高语义地图的空间精度以及时间一致性。
网络的训练是基于非常精确地相机姿态以及语义分割,所以可以采用监督学习。
Pose Network包含一个Pose CNN以及一个Pose GRU-RNN。
其中Pose CNN的输入是RGB图像I以及一个标签地图L。
输出是一个7维的向量,表示输入图像I与输入标签地图L之间的位姿关系,从而得到一个在3D Map中更精确的姿态.
分割网络结构:

首先基于RGB图像对该网络训练,然后加入标签地图数据进行微调(Fine Tune).
需要注意的是,当标签地图加入框架时,需要经过编码,即每一个像素经One-hot操作得到一个32维的Feature Representation。
然后得到的32维特征加入到RGB图像的第一层卷积输出中,且该层的Kernel数也是32个,从而平衡了两种数据的通道数(Channel Number)。
3. 端到端SLAM 结合深度增强学习 DRL
A. 使用DRL深度加强学习实现机器人自主导航
论文 Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning

深度强化学习中有两个较少被提及的问题:
1. 对于新的目标泛化能力不足,
2. 数据低效,比如说,模型需要几个(通常开销较大)试验和误差集合,使得其应用于真实世界场景时并不实用。
在这篇文章中,解决了这两个问题,并将我们的模型应用于目标驱动的视觉导航中。
为了解决第一个问题,我们提出了一个actor-critic演员评论家模型,它的策略是目标函数以及当前状态,能够更好地泛化。
为了解决第二个问题,我们提出了 AI2-THOR框架,它提供了一个有高质量的3D场景和物理引擎的环境。
我们的框架使得agent智能体能够采取行动并和对象之间进行交互。因此,我们可以高效地收集大量训练样本。
我们提出的方法
1)比state-of-the-art的深度强化学习方法收敛地更快,
2)可以跨目标跨场景泛化,
3)通过少许微调就可以泛化到真实机器人场景中(尽管模型是在仿真中训练的)
4)不需要特征工程,帧间的特征匹配和对于环境的特征重建,是可以端到端训练的。
B. 用于视觉导航的感知建图和规划
论文 Cognitive Mapping and Planning for Visual Navigation
我们提出了一个用于在陌生环境中导航的神经网络结构。
我们提出的这个结构以第一视角进行建图,并面向环境中的目标进行路径规划。
The Cognitive Mapper and Planner (CMP)主要依托于两个观点:
1.一个用于建图和规划的统一的联合架构中,建图由规划的需求所驱动的。
2. 引入空间记忆,使得能够在一个并不完整的观察集合的基础之上进行规划。
CMP构建了一个自上而下的belief map置信地图,
并且应用了一个可微的神经网络规划器,在每一个时间步骤中决策下一步的行动。
对环境积累的置信度使得可以追踪已被观察到的区域。
我们的实验表明CMP的性能优于reactive strategies反应性策略 和standard memory-based architectures
标准的基于记忆的体系结构 两种方法,
并且在陌生环境中表现良好。另外,CMP也可以完成特定的语义目标,
比如说“go to a chair”到椅子那儿去。
C. DeepVO:基于深度循环卷积神经网络的端到端视觉里程计 CNN+RNN
论文 End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks
DeepVO: Towards End-to-End Visual Odometry with Deep RecurrentConvolutional Neural Networks
本文使用深度递归卷积神经网络(RCNNs),提出了一种新颖的端到端单目VO的框架。
由于它是以端到端的方式进行训练和配置的,
因此它可以直接从一系列原始的RGB图像(视频)中计算得到姿态,而无需采用任何传统VO框架中的模块。 
基于RCNN,一方面它可以通过卷积神经网络(Convolutional Neural Network)自动学习VO问题的有效特征表示,
另一方面可以通过递归神经网络(Recurrent Neural Network)对时序模型(运动模型)、数据关联模型(图像序列)进行隐式建模。 
转载请注明原地址,万有文的博客:ewenwan.github.io 谢谢!




