
caffe使用 源码分析 依赖库分析 caffe glog gflags openBlas

主要类对象
caffe大致可以分为三层结构blob,layer,net。
数据的保存,交换以及操作都是以blob的形式进行的,
layer是模型和计算的基础,
net整和并连接layer,
solver则是模型的优化求解。 ## 一、数据Blob 是Caffe的基本数据结构, 4维的数组(Num, Channels, Height, Width)
设Blob数据维度为 number N x channel K x height H x width W,数据批次数量,通道数量,高宽尺寸
Blob是row-major 行优先 保存的,因此在(n, k, h, w)位置的值,
实际物理位置为((n * K + k) * H + h) * W + w,其中Number/N是batch size。
Blob 数据成员 data_指向实际存储数据的内存或显存块,shape_存储了当前blob的维度信息,diff_这个保存了反向传递时候的梯度信息。
data_at这个函数可以读取的存储在此类中的数据,diff_at可以用来读取反向传回来的误差。
尽量使用data_at(const vector<int>& index)来查找数据。
Reshape函数可以修改blob的存储大小,count用来返回存储数据的数量。
BlobProto类负责了将Blob数据进行打包序列化到Caffe的模型中。
Blob同时保存了data和diff(梯度),访问data或diff有两种方法:
1. const Dtype* cpu_data() const; //不修改值 指针指向常量 / gpu_data()
2. Dtype* mutable_cpu_data(); //修改值 / mutable_gpu_data()
Blob会使用SyncedMem(分配内存和释放内存类) 自动决定什么时候去copy data以提高运行效率,
通常情况是仅当gnu或cpu修改后有copy操作,文档里面给了一个例子:
using caffe::Blob; // 作为数据传输的媒介,无论是网络权重参数,还是输入数据,都是转化为Blob数据结构来存储
// 可以把Blob看成一个有4维的结构体(包含数据和梯度),而实际上,它们只是一维的指针而已,其4维结构通过shape属性得以计算出来。
// shared_ptr<SyncedMemory> data_ //数据
// shared_ptr<SyncedMemory> diff_ //梯度
// void Blob<Dtype>::Reshape(const int num, const int channels, const int height,const int width)
// 在更高一级的Layer中Blob用下面的形式表示学习到的参数:
// vector<shared_ptr<Blob<Dtype> > > blobs_;
// 这里使用的是一个Blob的容器是因为某些Layer包含多组学习参数,比如多个卷积核的卷积层。
// 以及Layer所传递的数据形式,后面还会涉及到这里:
// vector<Blob<Dtype>*> ⊥
// vector<Blob<Dtype>*> *top
一个实例,用以确定blob何时回复制数据:
// 假定数据在 假定数据在 CPU上进行初始化,我们有一个blob
const Dtype* foo;
Dtype* bar;
foo = blob.gpu_data(); // 数据从 CPU 复制到 复制到 GPU
foo = blob.cpu_data(); // 没有数据复制,两者都最新的内容
bar = blob.mutable_gpu_data(); // 没有数据复制
// ... 一些操作 ...
bar = blob.mutable_gpu_data(); // 仍在 GPU,没有数据复制
foo = blob.cpu_data(); // 由于GPU修改了数值,数据从 GPU 复制到 CPU
foo = blob.gpu_data(); // 没有数据复制,两者都最新的内容
bar = blob.mutable_cpu_data(); // 依旧没有数据复制
bar = blob.mutable_gpu_data(); // 数据从 CPU 复制到 GPU
bar = blob.mutable_cpu_data(); // 数据从 GPU 复制到 CPU
二、各种层实现 卷积 池化
在Layer中 输入数据input data用bottom表示,
输出数据 output data用top表示。
每一层定义了三种操作:
1. setup(Layer初始化),
2. forward(正向传导,根据input计算output),
3. backward(反向传导计算,根据output计算input的梯度)。
forward和backward有GPU(大部分)和CPU两个版本的实现。
using caffe::Layer;// 作为网络的基础单元,神经网络中层与层间的数据节点、前后传递都在该数据结构中被实现,
// 层类种类丰富,比如常用的卷积层、全连接层、pooling层等等,大大地增加了网络的多样性.
// NeuronLayer类 定义于neuron_layers.hpp中, 比如Dropout运算,激活函数ReLu,Sigmoid等.
// LossLayer类 定义于loss_layers.hpp中,其派生类会产生loss,只有这些层能够产生loss。
// 数据层 定义于data_layer.hpp中,作为网络的最底层,主要实现数据格式的转换。
// 特征表达层(我自己分的类)定义于vision_layers.hpp, 包含卷积操作,Pooling操作.
// 网络连接层和激活函数(我自己分的类)定义于common_layers.hpp,包括了常用的 全连接层 InnerProductLayer 类。
// 在Layer内部,数据主要有两种传递方式,正向传导(Forward)和反向传导(Backward)。Forward和Backward有CPU和GPU(部分有)两种实现。
// virtual void Forward(const vector<Blob<Dtype>*> &bottom, vector<Blob<Dtype>*> *top) = 0;
// virtual void Backward(const vector<Blob<Dtype>*> &top, const vector<bool> &propagate_down, vector<Blob<Dtype>*> *bottom) = 0;
// Layer类派生出来的层类通过这实现这两个虚函数,产生了各式各样功能的层类。
// Forward是从根据bottom计算top的过程,Backward则相反(根据top计算bottom)。
layer主要定义了三种运算,setup,forward,backward
在Layer内部,数据主要有两种传递方式,正向传导(Forward)和反向传导(Backward)。
Forward和Backward有CPU和GPU(部分有)两种实现。
Caffe中所有的Layer都要用这两种方法传递数据。
Layer类派生出来的层类通过实现这两个虚函数,产生了各式各样功能的层类。
Forward是从根据bottom计算top的过程,Backward则相反(根据top计算bottom)。
注意这里为什么用了一个包含Blob的容器(vector),
对于大多数Layer来说输入和输出都各连接只有一个Layer,然而对于某些Layer存在一对多的情况,
比如LossLayer和某些连接层。
在网路结构定义文件(*.proto)中每一层的参数bottom和top数目就决定了vector中元素数目。 ```asm layers {
bottom: "decode1neuron" // 该层底下连接的第一个Layer
bottom: "flatdata" // 该层底下连接的第二个Layer
top: "l2_error" // 该层顶上连接的一个Layer
name: "loss" // 该层的名字 type: EUCLIDEAN_LOSS //该层的类型
loss_weight: 0 } ```
三、网络Net 由各种层Layer组成的 无回路有向图DAG
Net是由一些列层组成的有向无环图DAG,
一个典型的Net开始于data layer ----> 从磁盘中加载数据----> 终止于loss layer。
(计算和重构目标函数。)
这个是我们使用Proto创建出来的深度网络对象,这个类负责了深度网络的前向和反向传递。
Layer之间的连接由一个文本文件描述。
网络模型初始化Net::Init()会产生blob和layer并调用 Layer::SetUp。
在此过程中Net会报告初始化进程(大量网络载入信息)。这里的初始化与设备无关。
在初始化之后通过Caffe::set_mode()设置Caffe::mode()来选择运行平台CPU或GPU,结果是相同的。 ```c using caffe::Net;// 作为网络的整体骨架,决定了网络中的层次数目以及各个层的类别等信息 // Net用容器的形式将多个Layer有序地放在一起,其自身实现的功能主要是对逐层Layer进行初始化, // 以及提供Update( )的接口(更新网络参数),本身不能对参数进行有效地学习过程。 // vector<shared_ptr<Layer<Dtype> > > layers_; // 同样Net也有它自己的 前向传播 和反向传播 // vector<Blob<Dtype>*>& Forward(const vector<Blob<Dtype>* > & bottom, Dtype* loss = NULL); // 前传得到 loss // void Net<Dtype>::Backward();// 反传播得到各个层参数的梯度 // 他们是对整个网络的前向和方向传导,各调用一次就可以计算出网络的loss了。 ```
以下是Net类的初始化方法NetInit函数调用流程: 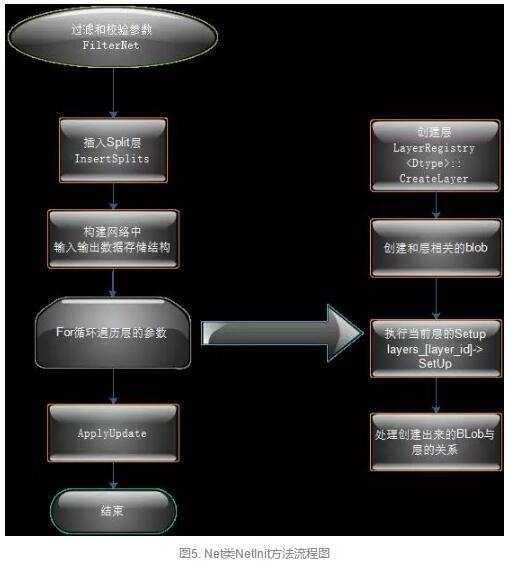
类中的关键函数简单剖析:
1). ForwardBackward:按顺序调用了Forward和Backward。
2). ForwardFromTo(int start, int end):执行从start层到end层的前向传递,采用简单的for循环调用, forward只要计算损失loss
3). BackwardFromTo(int start, int end):和前面的ForwardFromTo函数类似,调用从start层到end层的反向传递。
backward主要根据loss来计算梯度,caffe通过自动求导并反向组合每一层的梯度来计算整个网络的梯度。
4).ToProto函数完成网络的序列化到文件,循环调用了每个层的ToProto函数。
Net::Init()进行模型的初始化。
初始化主要实现两个操作:创建 blobs 和 layers 以搭建整个DAG网络,并且调用layers的SetUp()函数。
四、求解器Solver 各种数值优化的方法
Solver通过协调Net的前向计算和反向梯度计算来进行参数更新,从而达到loss的目的。
目前Caffe的模型学习分为两个部分:
1. 由Solver进行优化、更新参数;
2. 由Net计算出loss和gradient。
solver具体的工作:
1、用于优化过程的记录,创建 训练网络 和 测试网络。
2、用过 forward 和 backward 过程来迭代优化更新参数。
3、周期性的用测试网络评估模型性能。TestAll()
4、优化过程中记录模型和solver状态的快照。
一些参数的配置都在solver.prototxt格式的文件中: ```sh 1. ####训练样本###
训练数据集总共:121368 个图片
batch_szie:256
将所有样本处理完一次(称为一代,即epoch) 需要:121368/256 = 475 次迭代才能完成一次遍历数据集.
所以这里将 test_interval 设置为 475,即处理完一次所有的训练数据后,才去进行测试。
所以这个数要大于等于475.
如果想训练100代,则最大迭代次数为 47500;
- ####测试样本### 同理,如果有1000个测试样本, batch_size 为25, 那么需要40次才能完整的测试一次。 所以 test_iter 为40; 这个数要大于等于40.
-
####学习率### 学习率变化规律我们设置为随着迭代次数的增加,慢慢变低。 总共迭代47500次,我们将变化5次, 所以stepsize 设置为 47500/5=9500,即每迭代9500次,我们就降低一次学习率。
-
solver.prototxt 文件参数含义#############
net: “examples/AAA/train_val.prototxt” # 训练或者测试网络配置文件 test_iter: 40 # 完成一次测试需要的迭代次数 test_interval: 475 # 测试间隔 base_lr: 0.01 # 基础学习率 lr_policy: “step” # 学习率变化规律 gamma: 0.1 # 学习率变化指数 stepsize: 9500 # 学习率变化间隔 display: 20 # 屏幕显示间隔 max_iter: 47500 # 最大迭代次数 momentum: 0.9 # 权重加速更新动量 weight_decay: 0.0005 # 权重更新衰减因子 snapshot: 5000 # 保存模型间隔 snapshot_prefix: “models/A1/caffenet_train” # 保存模型的前缀 solver_mode: GPU # 是否使用GPU
stepsize 不能太小,如果太小会导致学习率再后来越来越小,达不到充分收敛的效果。
```c
using caffe::Solver;// 作为网络的求解策略,涉及到求解优化问题的策略选择以及参数确定方面,修改这个模块的话一般都会是研究DL的优化求解的方向。
// 包含一个Net的指针,主要是实现了训练模型参数所采用的优化算法,它所派生的类就可以对整个网络进行训练了。
// shared_ptr<Net<Dtype> > net_;
// 不同的模型训练方法通过重载函数ComputeUpdateValue( )实现计算update参数的核心功能.
// virtual void ComputeUpdateValue() = 0;
// 进行整个网络训练过程(也就是你运行Caffe训练某个模型)的时候,实际上是在运行caffe.cpp中的train( )函数,
// 而这个函数实际上是实例化一个Solver对象,初始化后调用了Solver中的Solve( )方法。
// 而这个Solve( )函数主要就是在迭代运行下面这两个函数,就是刚才介绍的哪几个函数。
// ComputeUpdateValue();
// net_->Update();
目录结构
caffe文件夹下主要文件: 这表示文件夹
data 用于存放下载的训练数据
docs 帮助文档
example 一些代码样例
matlab MATLAB接口文件
python Python接口文件
model 一些配置好的模型参数
scripts 一些文档和数据用到的脚本
下面是核心代码文件夹:
tools 保存的源码是用于生成二进制处理程序的,caffe在训练时实际是直接调用这些二进制文件。
include Caffe的实现代码的头文件
src 实现Caffe的源文件
后面的学习主要围绕后面两个文件目录(include和src)下的代码展开 # 源码结构
由于include和src两个目录在层次上基本一一对应因此主要分析src即可了解文件结构。
这里顺便提到一个有意思的东西,我是在Sublime上面利用SublimeClang插件分析代码的(顺便推荐下这插件,值得花点时间装)。
Sublime tx2 SublimeClang 参考配置: https://www.cnblogs.com/wxquare/p/4751297.html
在配置的时候发现会有错误提示找不到”caffe/proto/caffe.pb.h”,去看了下果然没有,但编译的时候没有报错,说明是生成过后又删除了,
查看Makefile文件后发现这里用了proto编译的,所以在”src/caffe/proto”下面用CMakeLists文件就可以编译出来了。 [Google Protocol Buffer 的使用和原理 ](https://www.ibm.com/developerworks/cn/linux/l-cn-gpb/)
src
gtest
google test一个用于测试的库,
你make runtest时看见的很多绿色RUN OK就是它,这个与caffe的学习无关,不过是个有用的库 ### caffe 关键的代码都在这里了
1. test 用gtest测试caffe的代码
2. util 数据转换时用的一些代码。
caffe速度快,很大程度得益于内存设计上的优化(blob数据结构采用proto)和对卷积的优化(部分与im2col相关).
3. proto 即所谓的“Protobuf”,全称“Google Protocol Buffer”,是一种数据存储格式,帮助caffe提速。
4. layers 深度神经网络中的基本结构就是一层层互不相同的网络了,
5. 这个文件夹下的源文件以及目前位置“src/caffe”中包含的我还没有提到的所有.cpp文件,
就是caffe的核心目录下的核心代码了。 ### caffe核心代码
1. /layers 此文件夹下面的代码全部至少继承了类Layer;
2. blob[.cpp .h] 基本的数据结构Blob类;
3. common[.cpp .h] 定义Caffe类;
4. data_transformer[.cpp .h] 输入数据的基本操作类DataTransformer;
5. internal_thread[.cpp .h] 使用boost::thread线程库;
6. layer_factory.cpp layer.h 层类Layer ;
7. net[.cpp .h] 网络结构类Net ;
8. solver[.cpp .h] 优化方法类Solver ;
9. syncedmem[.cpp .h] 分配内存和释放内存类CaffeMallocHost,用于同步GPU,CPU数据
层Layer
Layer是所有层的基类,在Layer的基础上衍生出来的有5种Layers:
1. 数据层 data_layer
2. 神经元层 neuron_layer
3. 损失函数层 loss_layer
4. 网络连接层和激活函数 common_layer 替换成各种层名字的文件
5. 特征表达层 vision_layer 也展开成各自层对应的文件
... 新版本caffe 把每种层类型都写了一个头文件和源文件
它们都有对应的[.hpp .cpp]文件声明和实现了各个类的接口。
在Layer中 输入数据input data用bottom表示,
输出数据 output data用top表示。
每一层军定义了三种操作:
1. setup(Layer初始化),
2. forward(正向传导,根据input计算output),
3. backward(反向传导计算,根据output计算input的梯度)。
forward和backward有GPU(大部分)和CPU两个版本的实现。
还有其他一些特有的操作
依赖库介绍
1. glog, google出的一个C++轻量级日志库
代码中充斥这类似
HECK_EQ(数字相等检查)、 CHECK_NE(不相等)、CHECK_LE(小于等于)、CHECK_LT(小于)、CHECK_GE(大于等于)、CHECK_GT(大于)
CHECK_NOTNULL(指针非空检查)、CHECK_STRNE()
CHECK_STREQ(字符串相等检查)、
CHECK_DOUBLE_EQ(浮点数相等检查)、
CHECK_GT(大于检查)
函数,
这就是glog里面的 (CHECK 宏) ,类似ASSERT()的断言。
当通过该宏指定的条件不成立的时候,程序会中止,并且记录对应的日志信息。
还有打印日志函数 LOG(INFO),日志输出到 stderr(标准错误输出) ### glog捕捉 程序段错误信息 在 caffe::GlobalInit(&argc, &argv); 有用到
捕捉 段错误 核心已转储 信息 core dumped 方便调试错误
// 通过 google::InstallFailureSignalHandler(); 即可注册,将 core dumped 信息输出到 stderr,如:
#include <glog/logging.h>
#include <string>
#include <fstream>
//将信息输出到单独的文件和 LOG(ERROR)
void SignalHandle(const char* data, int size)
{
std::ofstream fs("glog_dump.log",std::ios::app);
std::string str = std::string(data,size);
fs<<str;
fs.close();
LOG(ERROR)<<str;
}
class GLogHelper
{
public:
GLogHelper(char* program)
{
google::InitGoogleLogging(program);// 传入可执行文件吗
FLAGS_colorlogtostderr=true;
google::InstallFailureSignalHandler();
//默认捕捉 SIGSEGV 信号信息输出会输出到 stderr,可以通过下面的方法自定义输出方式:
google::InstallFailureWriter(&SignalHandle);
}
~GLogHelper()
{
google::ShutdownGoogleLogging();
}
};
void fun()
{
int* pi = new int;// 在堆中申请一个变量,由在栈中的指针pi指针指向
delete pi;//删除对应堆中的内存
pi = 0; // 指针置空
int j = *pi;// 对一个空指针进行解引用,报段错误
}
int main(int argc,char* argv[])
{
GLogHelper gh(argv[0]);//这个可以捕捉core dump的详细信息,可以定位到在fun()函数处出错
fun();
}
2.gflags ,是google的一个开源的处理命令行参数的库
首先需要 使用 gflags的宏:DEFINE_xxxxx(变量名,默认值,help-string) 定义命令行参数 ```c // 求解器prototxt文件名 DEFINE_string(solver, "",
"The solver definition protocol buffer text file."); ```
1. 首先需要include "gflags.h"(废话,-_-b)
#include <gflags/gflags.h>
2. 将需要的命令行参数使用gflags的宏:DEFINE_xxxxx(变量名,默认值,help-string) 定义在文件当中,注意全局域(放在文件最前面的部分)。
gflags支持以下类型:
DEFINE_bool: boolean 布尔量
DEFINE_int32: 32-bit integer 32位整形
DEFINE_int64: 64-bit integer 64位整形
DEFINE_uint64: unsigned 64-bit integer 64位无符号整形
DEFINE_double: double 64位浮点型
DEFINE_string: C++ string 字符串string ```c // 求解器prototxt文件名 DEFINE_string(solver, "",
"The solver definition protocol buffer text file."); ```
3. 在main函数中加入:(一般是放在main函数的头几行,越早了解用户的需求越好么^_^)
google::ParseCommandLineFlags(&argc, &argv, true);
argc 参数计数 counter
argv 参数列表 vector 字符串列表向量
第三个参数,如果设为true,则该函数处理完成后,argv中只保留argv[0],argc会被设置为1。
如果为false,则argv和argc会被保留,但是注意函数会调整argv中的顺序 ```c caffe::GlobalInit(&argc, &argv); // 原函数 void GlobalInit(int* pargc, char*** pargv) { // Google flags. namespace gflags = google; ::gflags::ParseCommandLineFlags(pargc, pargv, true); // Google logging. glog中的日志等级 ::google::InitGoogleLogging(*(pargv)[0]); // Provide a backtrace on segfault. ::google::InstallFailureSignalHandler();// glog的 异常捕获(段错误)处理 } ```
4. 这样,在后续代码中可以使用FLAGS_变量名访问对应的命令行参数了
printf("%s", FLAGS_mystr);
5. 最后,编译成可执行文件之后,用户可以使用:executable --参数1=值1 --参数2=值2 ... 来为这些命令行参数赋值。
./mycmd --var1="test" --var2=3.141592654 --var3=32767 --mybool1=true --mybool2 --nomybool3 ### gflags进阶使用
1. 在其他文件中使用定义的flags变量:
有些时候需要在main之外的文件使用定义的flags变量,
这时候可以使用宏定义DECLARE_xxx(变量名)声明一下(就和c++中全局变量的使用是一样的,extern一下一样)
2. 定制你自己的help信息与version信息:(gflags里面已经定义了-h和--version,你可以通过以下方式定制它们的内容)
version信息:使用google::SetVersionString设定,使用google::VersionString访问
help信息:使用google::SetUsageMessage设定,使用google::ProgramUsage访问
注意:google::SetUsageMessage和google::SetVersionString必须在google::ParseCommandLineFlags之前执行
3. gtest Google的开源C++单元测试框架
gtest Google的开源C++单元测试框架,caffe里面test代码中大量用到,网上教程也是一大堆。 [参考](http://www.cnblogs.com/coderzh/archive/2009/04/06/1426755.html)
4. 关于CPU加速
Caffe推荐的BLAS(Basic Linear Algebra Subprograms)有三个选择ATLAS,Intel MKL,OpenBLAS。
其中ATLAS是caffe是默认选择开源免费,如果没有安装CUDA的不太推荐使用,因为CPU多线程的支持不太好;
Intel MKL是商业库要收费,我没有试过但caffe的作者安装的是这个库,估计效果应该是最好的;
OpenBLAS开源免费,支持CPU多线程,我安装的就是这个。
1. 安装ATLAS
sudo apt-get install libatlas-base-dev
2. 安装OpenBLAS
sudo apt-get install libopenblas-base ## BLAS与boost::thread加速 ## BLAS http://www.netlib.org/blas/blasqr.pdf
BLAS (Basic Linear Algebra Subprograms, 基础线性代数子程序库),
是一个应用程序接口(API)标准,说的简单点就是向量、矩阵之间乘加这些运算。
BLAS虽然本身就有实现但 效率不高,因此有大量的开源或商业项目对BLAS进行优化,
比如OpenBLAS(开源),Intel MKL(收费),ATLAS(开源)。
我用的是OpenBLAS这个库。 ## OpenBLAS [参考](https://www.leiphone.com/news/201704/Puevv3ZWxn0heoEv.html)
OpenBLAS是C语言实现的,这个库安装比较简单,如上面,唯一的一个问题是使用方法。
前面介绍BLAS提供了接口,文档在这里 http://www.netlib.org/blas/blasqr.pdf
这个文档中:
BLAS 1级 ,Level 1: 是vector与vector的操作, 向量与向量, 主要做向量与向量间的dot或乘加运算,对应元素的计算
BLAS 2级, Level 2: 是vector与matrix的操作, 向量与矩阵, 就类似下图中蓝色部分所示,矩阵A*向量x, 得到一个向量y。
BLAS 3级,Level 3: 是matrix与matrix的操作, 矩阵与矩阵, 最典型的是A矩阵*B矩阵,得到一个C矩阵。由矩阵的宽、高,得到一个m*n的C矩阵。
每个函数的开头有一个x表示精度比如替换成 s表示float类型(实数),d表示double类型,c表示复数。
其实虽然函数很多但其实使用方法大同小异,BLAS之所以分的这么细(区分到对称矩阵,三角矩阵)是为了方便针对不同的情况做优化。
所以其实搞清楚最关键的矩阵与矩阵的运算就已经理解了一大半。 

基于矩阵类学习的深度学习,有90%或者更多的时间是通过BLAS来操作的。
当然,随着新的算法出现,卷积层对3*3的卷积核有专门的算法,
或者用FFT类类算法也可以做,但是在通用上,展矩阵来做也非常广泛。
针对开源的而言,有如下几种,之前比较知名的是GoToBLAS,和OpenBLAS有很深的渊源,但是在2010年终止开发了. 
矩阵相乘
https://github.com/xianyi/OpenBLAS/wiki/User-Manual
以dgemm为例,全称为double-precision generic matrix-matrix muliplication,就是矩阵相乘,
在OpenBLAS中的声明是:
A * B = C
[M K] * [K N] = [M N] ```c cblas_dgemm(const enum CBLAS_ORDER Order, // 指定矩阵的存储方式如RowMajor 行优先/列优先
const enum CBLAS_TRANSPOSE TransA, // A运算后是否转置
const enum CBLAS_TRANSPOSE TransB, // B运算后是否转置
const blasint M, // A的行数
const blasint N, // B的列数
const blasint K, // A的列数
const double alpha, // 公式中的alpha
const double *A, // A
const blasint lda, // A一行的存储间隔
const double *B, // B
const blasint ldb, // B一行的存储间隔
const double beta, // 公式中的beta
double *C, // C
const blasint ldc) // C一行的存储间隔 ``` 因为这里的A、B、C矩阵都是以一维数组的形式存储所以需要告诉函数他们一行的存储间隔就是lda、ldb、ldc它们。
示例: ```c #include <cblas.h> #include <stdio.h>
void main()
{
int i=0;
double A[6] = {1.0,2.0,1.0,-3.0,4.0,-1.0};// 32
double B[6] = {1.0,2.0,1.0,-3.0,4.0,-1.0};// 23
double C[9] = {.5,.5,.5,.5,.5,.5,.5,.5,.5};// 3*3
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans,3,3,2,1,A, 3, B, 3,2,C,3);
for(i=0; i<9; i++) printf(“%lf “, C[i]); printf(“\n”); } 编译: gcc -o test_cblas_open test_cblas_dgemm.c -I /your_path/OpenBLAS/include/ -L/your_path/OpenBLAS/lib -lopenblas -lpthread -lgfortran
## Boost 相当强大的C++拓展库
用百度百科的话说,Boost库是一个经过千锤百炼、可移植、
提供源代码的C++库,作为标准库的后备,是C++标准化进程的发动机之一。
实际感受就是一个相当强大的C++拓展库,很多C++标准库里面没有的功能得以实现。
最近就用到了ublas,thread,date_time这三个模块。这里做一些简要的介绍。
[参考](https://yufeigan.github.io/2015/01/02/Caffe%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B05-BLAS%E4%B8%8Eboost-thread%E5%8A%A0%E9%80%9F/)
## ublas boost的BLAS实现 矩阵运算
调用位置boost::numeric::ublas,虽然速度一般,
但用起来非常方便可以直接用 + - 运算符号操作,还可以直接用 << >> 等标准输入输出流。
## date_time 计时
在我计算多线程运行时间的时候发现标准C++提供的std::clock_t,
对于多CPU跑线程的情况会把几个CPU的时间加在一起,
所以采用了 boost::posix_time::ptime 这种类型计数。
解决了计时不准确的问题。
## thread 线程库 是一个跨平台的线程封装库
Boost提供的thread虽然功能据说不是非常强大,
但是由于使用C++的思想重新设计,使用起来相对比较方便。
网上文档非常多,比如:
[1. C++ Boost Thread 编程指南](http://www.cnblogs.com/chengmin/archive/2011/12/29/2306416.html)
[2. Boost::Thread使用示例](https://blog.csdn.net/zhuxiaoyang2000/article/details/6588031)
### 1 创建线程
```c
#include <boost/thread/thread.hpp>
#include <iostream>
void hello()
{
std::cout<<"Hello world, I'm a thread!"<<std::endl;
}
int main()
{
boost::thread thrd(&hello);// 传入需要线程执行的函数的指针
thrd.join();
system("pause");
return 0;
}
2 避免不同线程同时访问共享区域 互斥体(mutex,mutual exclusion的缩写)
当一个线程想要访问共享区时,首先要做的就是锁住(lock)互斥体。
如果其他的线程已经锁住了互斥体,那么就必须先等那个线程将互斥体解锁,
这样就保证了同一时刻只有一个线程能访问共享区域。
Boost线程库支持两大类互斥体,包括简单互斥体(simple mutex)和递归互斥体(recursive mutex)。
如果同一个线程对互斥体上了两次锁,就会发生死锁(deadlock),也就是说所有的等待解锁的线程将一直等下去。
有了递归互斥体,单个线程就可以对互斥体多次上锁,
当然也必须解锁同样次数来保证其他线程可以对这个互斥体上锁。
一个线程可以有三种方法来对一个互斥体加锁:
一直等到没有其他线程对互斥体加锁。
如果有其他互斥体已经对互斥体加锁就立即返回。
一直等到没有其他线程互斥体加锁,直到超时。
Boost线程库提供了6中互斥体类型,下面是按照效率进行排序:
boost::mutex,
boost::try_mutex,
boost::timed_mutex,
boost::recursive_mutex,
boost::recursive_try_mutex,
boost::recursive_timed_mutex ```c
#include <boost/thread/thread.hpp>
#include <boost/thread/mutex.hpp>
#include <iostream>
boost::mutex io_mutex;// 互斥体
struct count
{
count(int id) : id(id) {}
void operator()()
{
for(int i = 0; i < 10; ++i)
{
boost::mutex::scoped_lock lock(io_mutex);// 对互斥体上锁
std::cout<<id<<": "<<i<<std::endl;
}
}
int id;
};
int main()
{
boost::thread thrd1(count(1));
boost::thread thrd2(count(2));
thrd1.join();
thrd2.join();
system("pause");
return 0;
} ```
只让一个线程输出信息到屏幕:
boost::mutex io_mutex;// 互斥体
void foo(){
{
boost::mutex::scoped_lock lock(io_mutex);//上锁
std::cout << "something output!" << std::endl;
}
// something to do!
}
// 用这种方法多个函数在对统一个数据操作的时候就不会有冲突了。
线程的并行化 boost::thread_group
boost::thread_group group;
for (int i = 0; i < 15; ++i)
group.create_thread(aFunctionToExecute);
group.join_all();// 当执行join_all()的时候才是真正的并行了程序。
成员函数没有实例但又要传参的方法
编译时候错误:error: reference to non-static member function must be called; did you mean to call it with no arguments?
查了Google发现是因为我定义的类中的成员函数用group.create_thread()中调用了没有实例化的成员函数解决方法是使用std::bind
group.create_thread(boost::bind(&myfunction, this)); ## Caffe 中的 SyncedMem gpu与cpu内存同步 [参考](https://xmfbit.github.io/2018/01/12/caffe-syncedmem/) ### SyncedMem的作用
Blob是一个多维的数组,可以位于内存,也可以位于显存(当使用GPU时)。
一方面,我们需要对底层的内存进行管理,包括何何时开辟内存空间。
另一方面,我们的训练数据常常是首先由硬盘读取到内存中,
而训练又经常使用GPU,最终结果的保存或可视化又要求数据重新传回内存,
所以涉及到Host和Device内存的同步问题。
同步的实现思路
在SyncedMem的实现代码中,作者使用一个枚举量head_来标记当前的状态。如下所示:
// in SyncedMem
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
// 使用过Git吗? 在Git中那个标志着repo最新版本状态的变量就叫 HEAD
// 这里也是一样,标志着最新的数据位于哪里
SyncedHead head_;
这样,利用head_变量,就可以构建一个状态转移图,在不同状态切换时进行必要的同步操作等。
![]()
Caffe中的BatchNorm实现 减去均值除以方差的方法进行归一化
对于网络的输入层,我们可以采用减去均值除以方差的方法进行归一化,对于网络中间层,BN可以实现类似的功能。 
caffe 中分成两个部分,BatchNorm层(去均值除以方差归一化) 和 Scale层(平移+缩放) ``` layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
} } layer {
bottom: "conv1"
top: "conv1"
name: "scale_conv1"
type: "Scale"
scale_param {
bias_term: true
} } ```
prototxt
文件的可视化
1.使用在线工具netscope。
https://ethereon.github.io/netscope/quickstart.html
2.使用自带draw_net.py脚本。
参考:
http://www.cnblogs.com/zjutzz/p/5955218.html
caffe绘制网络结构图
http://yanglei.me/gen_proto/
另一个在线工具。
caffe 模型配置文件 prototxt 详解
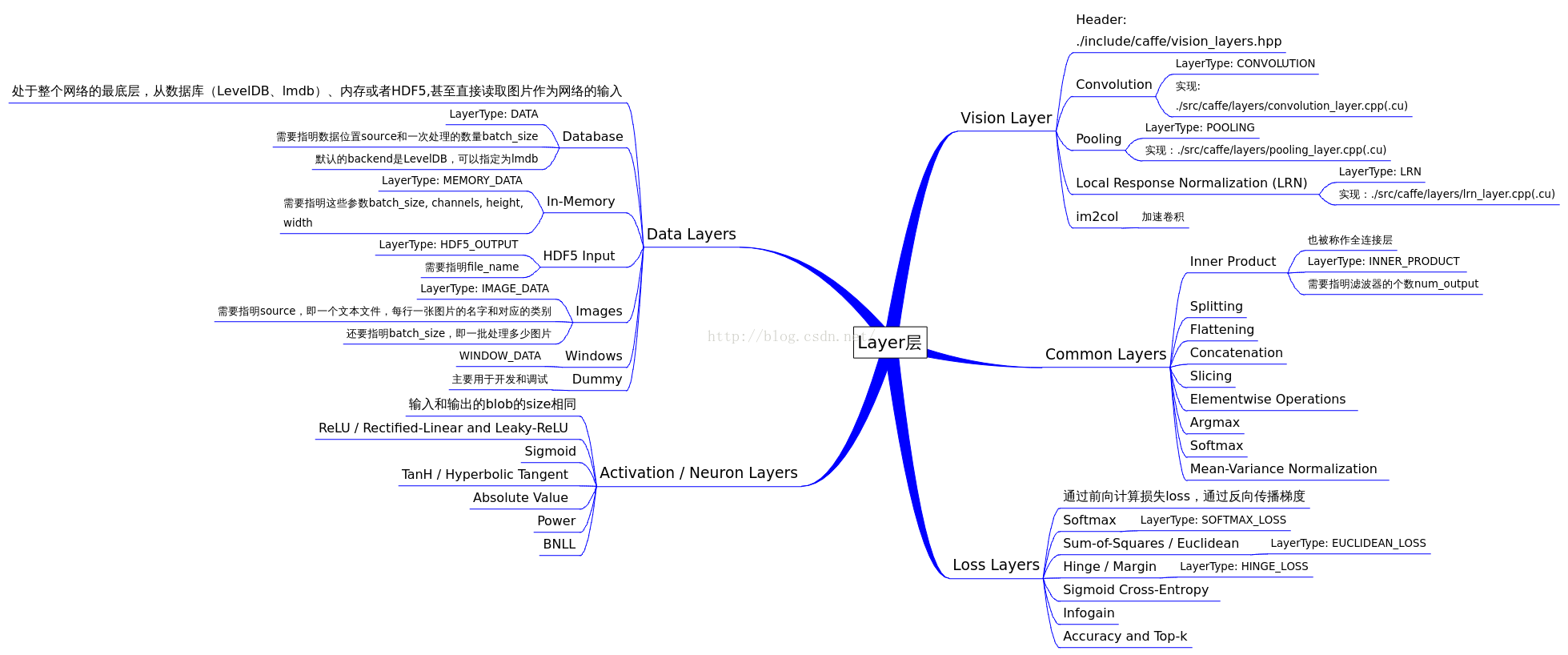
caffe 中 BatchNorm层 要和 Scale 层一起用才有 批规范化的效果
批规范化:
1) 输入归一化 x_norm = (x-u)/std, 其中u和std是个累计计算的均值和方差。
2)y=alpha×x_norm + beta,对归一化后的x进行比例缩放和位移。其中alpha 和beta是通过迭代学习的。
caffe中的bn层其实只做了第一件事;
scale 层做了第二件事;
scale层里为什么要设置bias_term=True,这个偏置就对应2)件事里的beta。
Caffe深入分析(源码)
1. Caffe的整体流程图
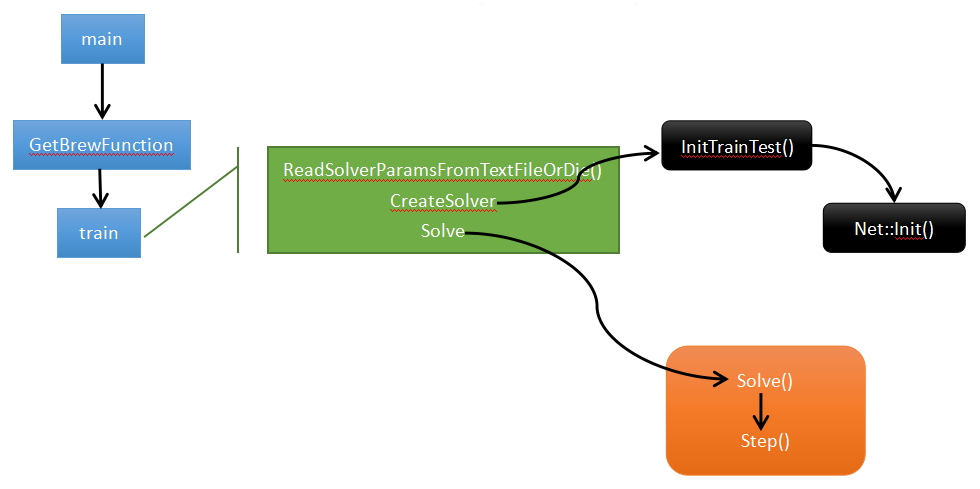 caffe.cpp 程序入口:main()
caffe.cpp 程序入口:main()
...
int main(int argc, char** argv) {
.....
return GetBrewFunction(caffe::string(argv[1]))();
....
}
g_brew_map实现过程,首先通过 typedef定义函数指针 typedef int (*BrewFunction)();
这个是用typedef定义函数指针方法。
这个程序定义一个BrewFunction函数指针类型,
在caffe.cpp 中 BrewFunction 作为GetBrewFunction()函数的返回类型,
可以是 train(),test(),device_query(),time() 这四个函数指针的其中一个。
在train(),test(),中可以调用solver类的函数,从而进入到net,进入到每一层,运行整个caffe程序。
然后对每个函数注册。 ```c RegisterBrewFunction(train) RegisterBrewFunction(test) RegisterBrewFunction(device_query) RegisterBrewFunction(time) ```
train: 训练或者调整一个模型
test : 在测试集上测试一个模型
device_query : 打印GPU的调试信息
time: 压测一个模型的执行时间
如果需要,可以增加其他的方式,然后通过RegisterBrewFunction()函数注册一下即可。 ## 2. train()函数 ```c // 接着调用train()函数,train函数中主要有三个方法ReadSolverParamsFromTextFileOrDie、CreateSolver、Solve。 // Train / Finetune a model. int train() { ...... caffe::SolverParameter solver_param; caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param);//从-solver参数文件,读取solver_param // 解析-solver指定的solver.prototxt的文件内容到solver_param中 ...... //初始化网络======================================================== shared_ptr<caffe::Solver<float> > solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));
// 从参数创建solver,同样采用 string 到 函数指针 的 映射实现,用到了工厂模式
// CreateSolver() -> solver_factory.hpp中
// 首先需要知道的是solver是一个基类,继承自它的类有SGD等,下面的实现就可以根据param的type构造一个指向特定solver的指针,比如SGD
// const string& type = param.type();
// CreatorRegistry& registry = Registry();
// return registry[type](param);
// 此处工厂模式和一个关键的宏REGISTER_SOLVER_CLASS(SGD)发挥了重要作用.
// 注册相关的Solver函数 到 registry[] 字符串:函数指针 map键值对
// 新建一个Solver对象 -> Solver类的构造函数 -> 新建Net类实例 -> Net类构造函数 -> 新建各个layer的实例 -> 具体到设置每个Blob
// 构建solver和net,该函数是初始化的入口,会通过执行Solver类的构造函数 在solver.cpp中 105行左右,
// 调用 void Solver<Dtype>::Init(const SolverParameter& param),
// 该函数内有InitTrainNet()、InitTestNets()。
// 对于InitTrainNet函数,会执行 Net类的初始化:
// shared_ptr<Net<Dtype> > net_;
// net_.reset(new Net<Dtype>(net_param));
// 调用Net类的构造函数,该构造函数会执行Init()操作 net.cpp 中38行左右.
// 1. 过滤和校验参数 FIlterNet() 将模型参数文件(*.prototxt)中的不符合规则的层去掉(微调时,部分层不一致)============
// 2. 插入Split层 InsertSplits 作用是对于底层的一个输出blob对应多个上层的情况,则要在加入分裂层,形成新的网络。========
// 原因是多个层反传给该blob的梯度需要累加
// 3. 构建网络中的输入输出数据结构 bottom_vecs_ top_vecs_
// 4. For训练遍历每一层的参数
(创建层 CreateLayer(),创建层相关的blob, AppendBottom()、AppendTop()
执行当前层的Setup( layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);))
创建数据关系
// 5. 应用更新 ApplyUpdate
// 6. 结束
// 网络初始化后 CreateSolver()执行完成后,接下来是具体训练过程, // 执行 Solve()函数: Step()—>结束 solver.cpp 276行=============
if (FLAGS_snapshot.size()) {//迭代snapshot次后保存模型一次
LOG(INFO) « “Resuming from “ « FLAGS_snapshot;
solver->Restore(FLAGS_snapshot.c_str());// 从snapshot的文件中恢复成网络,从而缩短了训练时间。
} else if (FLAGS_weights.size()) {//若采用finetuning,则拷贝weight到指定模型
CopyLayers(solver.get(), FLAGS_weights);
}
// 多gpu训练 数据同步
// 因为GPU的个数>1,首先会执行P2PSync类的构造函数,然后执行run()函数
if (gpus.size() > 1) {
caffe::P2PSync
* 多gpu数据交换同步
参考 http://www.cnblogs.com/liuzhongfeng/p/7809689.html
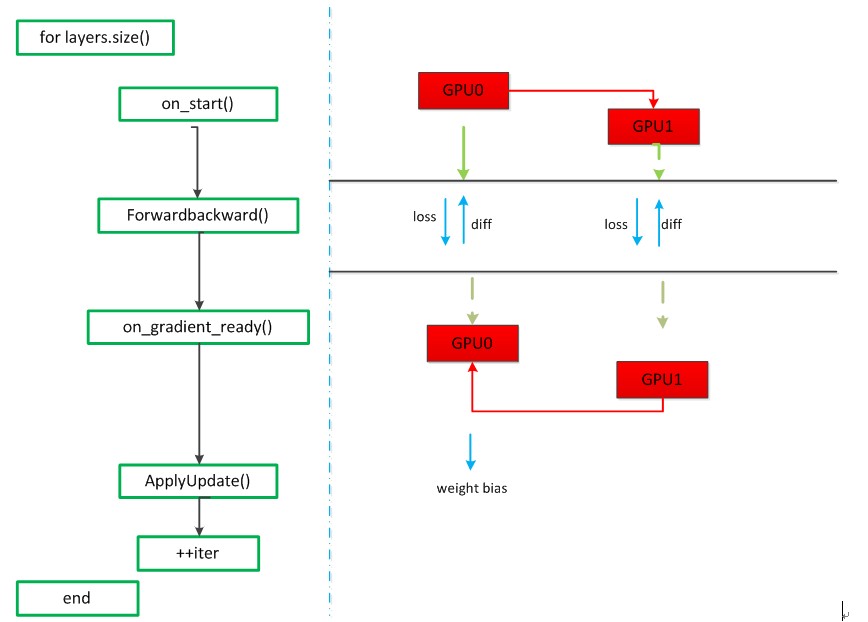
在run()函数中,
首先会执行compute()函数,
该函数的作用是产生GPU Pairs,
GPU Pairs的含义是[parent:child],
对于2个GPU而言,GPU Pairs为[-1:0],[0:1],
默认根GPU的parent是其本身。
然后通过一个for循环构建GPU树,
对于2个GPU而言,GPU树如下图所示:

接下来调用一个for循环为每个GPU开启一个线程,值得注意的是for循环是从i=1开始的,
即为每个子GPU单独开启一个线程(这里为GPU1开启一个线程),也就是调用 StartInternalThread() 函数.
该函数接着会执行 entry() 函数.
该函数又会去调用 InternalThreadEntry() 函数,该函数是正式进入迭代运算的入口.
solver_->Step(solver_->param().max_iter() - initial_iter_);
### 3. 初始化网络
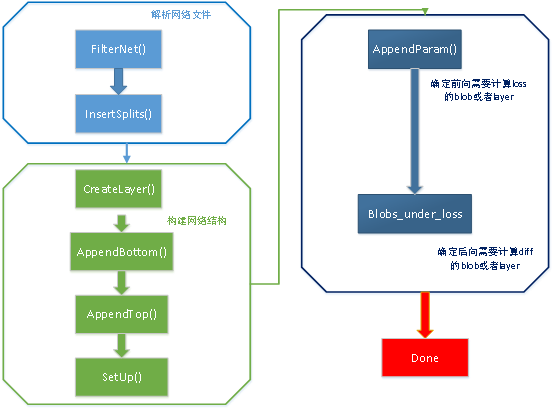
从图中可以看出网络层的构建分为三个主要部分:解析网络文件、开始建立网络层、网络层需要参与计算的位置。
1. 过滤和校验参数 FIlterNet() 将模型参数文件(*.prototxt)中的不符合规则的层去掉(微调时,部分层不一致)============
2. 插入Split层 InsertSplits 作用是对于底层的一个输出blob对应多个上层的情况,则要在加入分裂层,形成新的网络。========
原因是多个层反传给该blob的梯度需要累加,
例如:LeNet网络中的数据层的top label blob对应两个输入层,分别是accuracy层和loss层,那么需要在数据层在插入一层。
如下图:
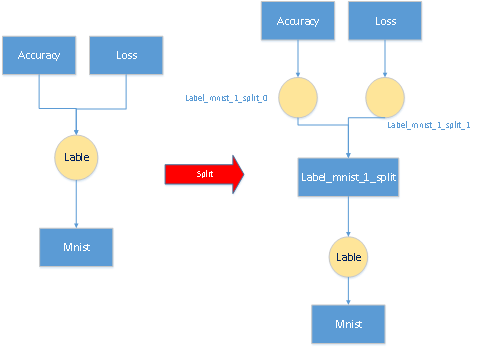
## 4. Solver<Dtype>::Solve() 的具体内容和代码:
```c
// 恢复之前保存的 slver状态===================================================
if (resume_file) {
LOG(INFO) << "Restoring previous solver status from " << resume_file;
Restore(resume_file);
}
// 更新步骤=================================================================
Step(param_.max_iter() - iter_);
// 保存weights=============================================================
if (param_.snapshot_after_train()
&& (!param_.snapshot() || iter_ % param_.snapshot() != 0)) {
Snapshot();
}
// 打印显示 loss信息=========================================================
if (param_.display() && iter_ % param_.display() == 0) {
int average_loss = this->param_.average_loss();
Dtype loss;
net_->Forward(&loss);
UpdateSmoothedLoss(loss, start_iter, average_loss);
LOG(INFO) << "Iteration " << iter_ << ", loss = " << smoothed_loss_;
}
// 进行测试 分分类(Top5)和检测网络(mAP)========================================
if (param_.test_interval() && iter_ % param_.test_interval() == 0) {
TestAll();
}
5. Step函数,具体内容和代码
// 将net_中的Bolb梯度参数置为零 ==========================
net_->ClearParamDiffs();
// 测试网络===================================================
if (param_.test_interval() && iter_ % param_.test_interval() == 0
&& (iter_ > 0 || param_.test_initialization())
&& Caffe::root_solver()) {
TestAll();
if (requested_early_exit_) {
// Break out of the while loop because stop was requested while testing.
break;
}
}
// 多gpu情况处理============================
// 参考 http://www.cnblogs.com/liuzhongfeng/p/7809689.html
for (int i = 0; i < callbacks_.size(); ++i) {
// 首先根GPU(GPU0)有整个网络的网络参数,callbacks_.size()指的是GPU树的parent的个数(在这里是1)
callbacks_[i]->on_start();
// on_start()函数的作用就是把根GPU(GPU0)的网络参数分发到每一个子GPU(GPU1),GPU1会先进入这个函数
// 等待从父GPU更新过来,P2PSync<Dtype> *parent = queue_.pop(); 取队列中的第一个gpu节点为根gpu
}
// 正向传导和反向传导,并计算loss =============================================
for (int i = 0; i < param_.iter_size(); ++i) {// batch 一个批次
loss += net_->ForwardBackward();// loss 求和
// net.hpp
// Forward(&loss);//正向传播 -> ForwardFromTo() -> 每个layer的Forward( layers_[i]->Forward() )
// Backward(); //反向传播 -> BackwardFromTo() -> 每个layer的Backward( layers_[i]->Backward() )
// backward主要根据loss来计算梯度,caffe通过自动求导并反向组合每一层的梯度来计算整个网络的梯度。
}
loss /= param_.iter_size(); // loss 均值
// 数值滤波 平滑loss =============================================================
// 为了输出结果平滑,将临近的average_loss个loss数值进行平均,存储在成员变量smoothed_loss_中
UpdateSmoothedLoss(loss, start_iter, average_loss);
// BP算法更新权重 ================================================================
ApplyUpdate(); // 调用SGDSolver::ApplyUpdate()成员函数进行权重更新
// 保存weights文件===============================================================
if ((param_.snapshot()
&& iter_ % param_.snapshot() == 0
&& Caffe::root_solver()) ||
(request == SolverAction::SNAPSHOT)) {
Snapshot();// Snapshot的存储格式有两种,分别是BINARYPROTO格式和hdf5格式
// SnapshotToHDF5();
// -> Solver<Dtype>::SnapshotToBinaryProto() -> net_->ToProto()
// ToProto函数完成网络的序列化到文件,循环调用了每个层的ToProto函数, 保存每一层的参数
}
6. BP算法更新权重 SGDSolver::ApplyUpdate()
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate()
{
// 获取当前学习速率 ====================================================
Dtype rate = GetLearningRate();
// 显示学习率===========================================================
if (this->param_.display() && this->iter_ % this->param_.display() == 0)
{
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
}
// 梯度抑制=============================================================
// 在计算当前梯度的时候,如果该值超过了阈值 clip_gradients,则将梯度直接设置为该阈值
// 此处阈值设为-1,即不起作用
ClipGradients();
// 逐层更新网络中的可学习层的参数
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id)
{
// 归一化 ===============================================================
Normalize(param_id);// -> caffe_scal() -> cblas_dscal()
// L1/ L2范数 正则化 ====================================================
// L1/ L2范数 正则化 添加衰减权重 (local_decay = weight_decay * net_params_weight_decay[param_id])
Regularize(param_id); // -> caffe_axpy() -> cblas_daxpy()
// 随机梯度下降法计算更新值 =================================================================
// SGDSolver<Dtype>::ComputeUpdateValue()
// RMSPropSolver<Dtype>::ComputeUpdateValue()
// NesterovSolver<Dtype>::ComputeUpdateValue()
// AdamSolver<Dtype>::ComputeUpdateValue()
// AdaGradSolver<Dtype>::ComputeUpdateValue()
// AdaDeltaSolver<Dtype>::ComputeUpdateValue()
ComputeUpdateValue(param_id, rate); //
// caffe_cpu_axpby() ( -> cblas_daxpby() ) -> caffe_copy() ( -> memcpy(Y, X, sizeof(Dtype) * N); )
}
// 更新权重 ===============================================================================
this->net_->Update(); // layer_names_[param_layer_indices_[param_owner].first];
}
ApplyUpdate
转载请注明原地址,万有文的博客:ewenwan.github.io 谢谢!




